A Python-based ETL (Extract, Transform, Load) pipeline developed as part of my Data Engineering learning path.
The project focuses on extracting data from multiple file formats, transforming it according to business rules, and loading the processed data into a structured output file, while logging each step of the proces
ETL Process Overview
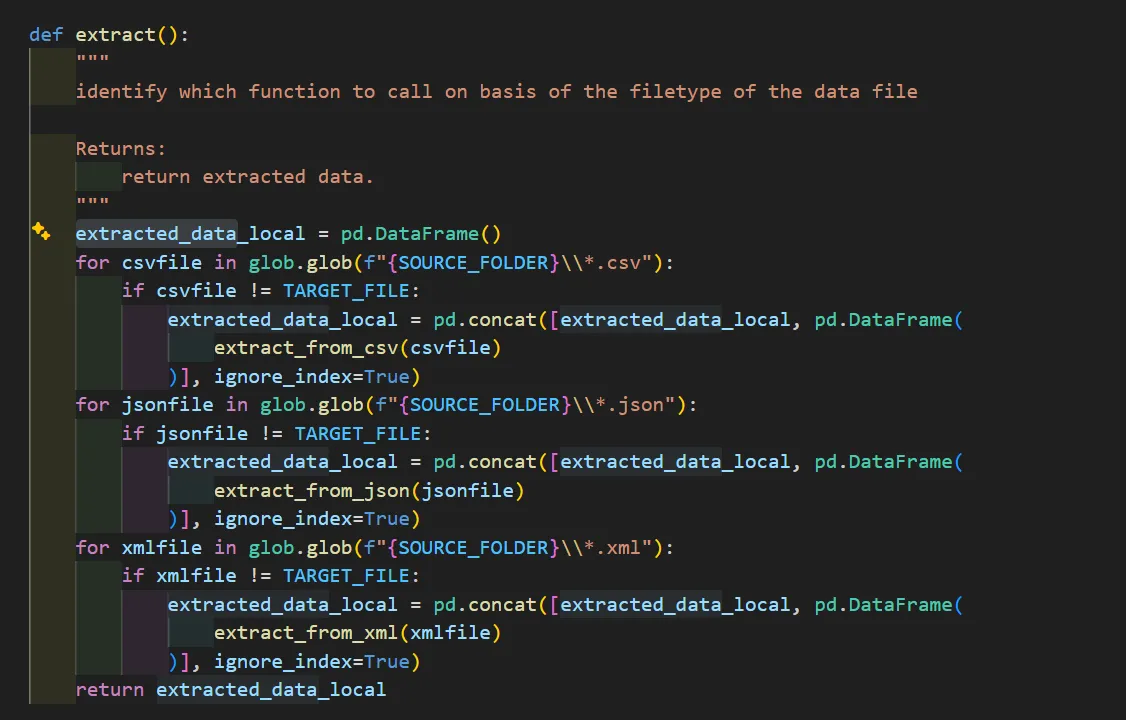
Extract
Data is extracted from multiple source formats, including CSV, JSON, and XML files.
The pipeline dynamically identifies source files and applies the appropriate extraction logic for each format, consolidating the data into a unified structure.
Data Handling & Structure
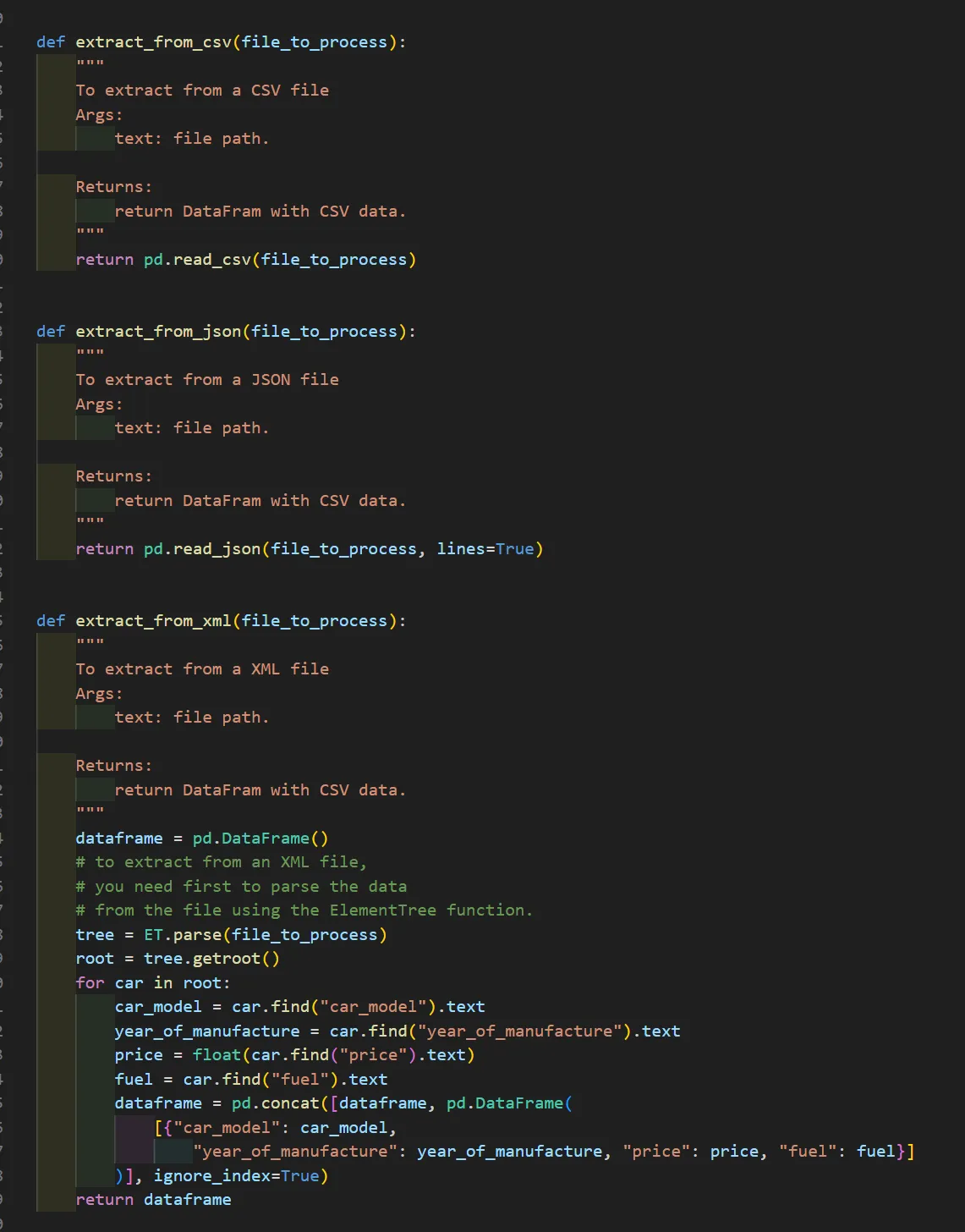
XML data is parsed using Python’s XML processing libraries and converted into tabular structures.
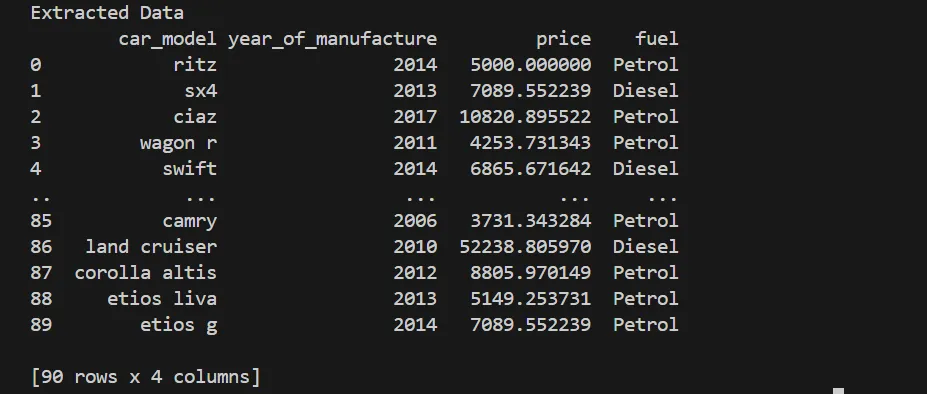
Extracted datasets from different formats are combined using pandas DataFrames, enabling consistent data manipulation and transformation across sources.
Transform
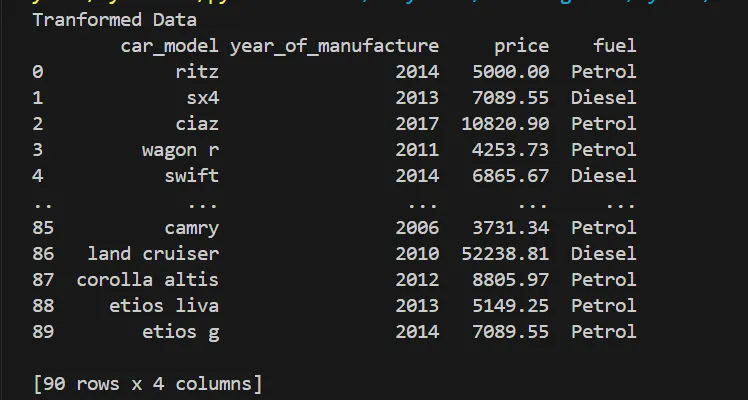
During the transformation phase, data is cleaned and normalized according to defined requirements.
In this project, numerical values such as prices are transformed and standardized to ensure consistency before loading.

Load
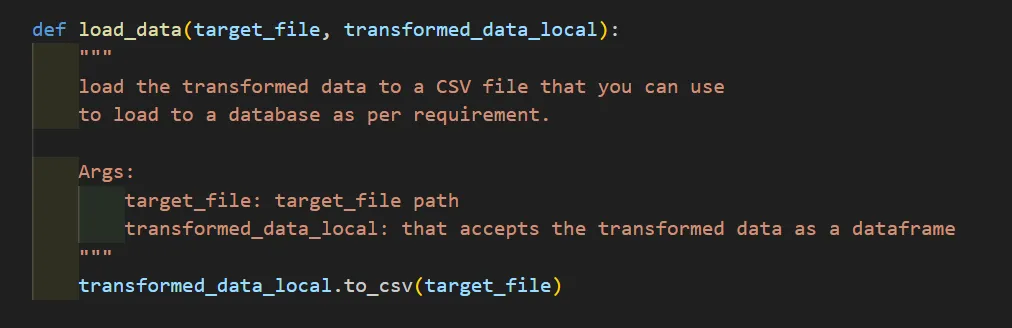
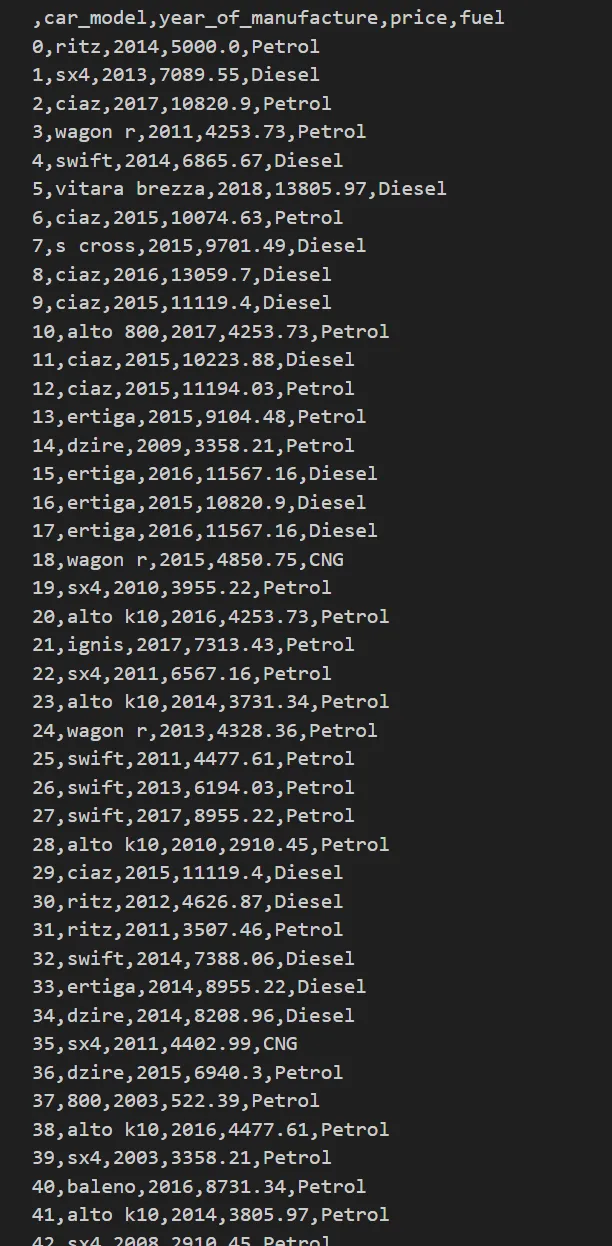
The transformed data is exported into a CSV file, making it ready for further processing or loading into a database or analytics workflow.
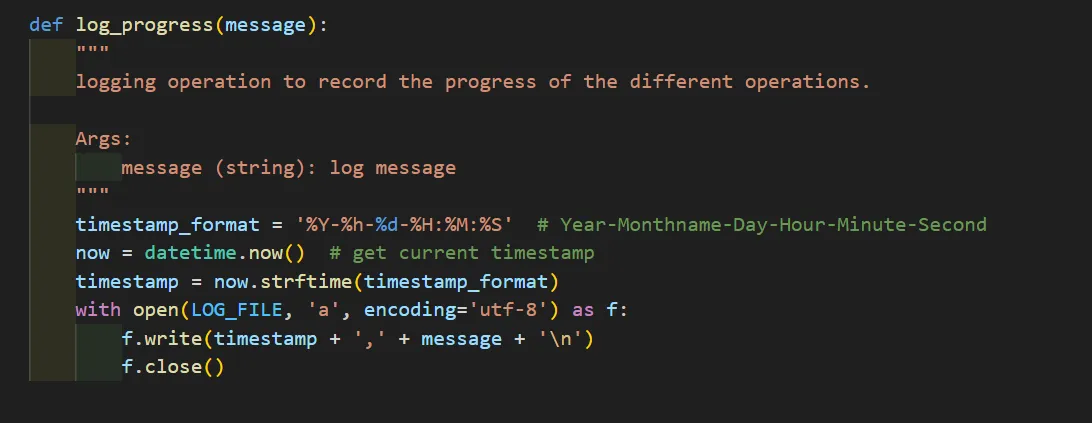
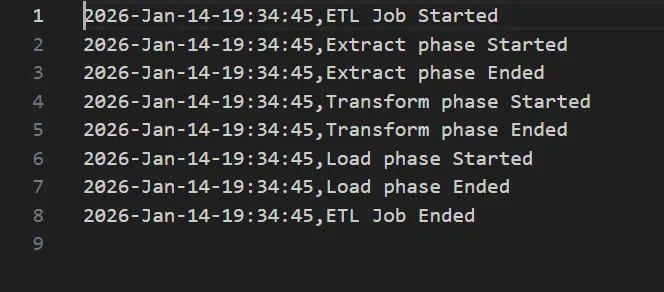
Logging & Monitoring
The pipeline includes a logging mechanism that records the progress of each ETL phase (Extract, Transform, Load), along with timestamps, allowing visibility into the execution flow and easier debugging.